Gestelltes Problem
Da ich zum Ausmalen (siehe Computergrafik) gerne Bitmaps mit möglichst vielen Einzelflächen als Ausgangsbasis nehme, dachte ich daran, dass doch zur Abwechslung einmal 3-dimensionale Objekte interessant wären. Solche Programme hab’ ich schon früher geschrieben, allerdings in Turbo-Pascal, einer Sprache die damals auf IBM-kompatiblem PC’s mit MS-DOS wirklich unschlagbar war, den Sprung zu Windows aber nicht geschafft hat. Mitte der 80er war das für mich an der Uni als Darstellung von Elektronenorbitalen (Kugelfunktionen) eine Übungsaufgabe in theoretischer Physik. Entweder die Darstellung der Kugelfunktionen am PC oder eine “schriftliche Aufgabe”. Damals hab’ ich mich in drei Millisekunden für die Programmieraufgabe entschieden. Der Professor meinte dann übrigens zu meinen Ausdrucken “Das ist die beste Darstellung der Kugelfunktionen, die ich jemals gesehen habe. Wie haben Sie das gemacht?”
Es ging jetzt also darum, diese Darstellung in C++ zu implementieren.
Algorithmus
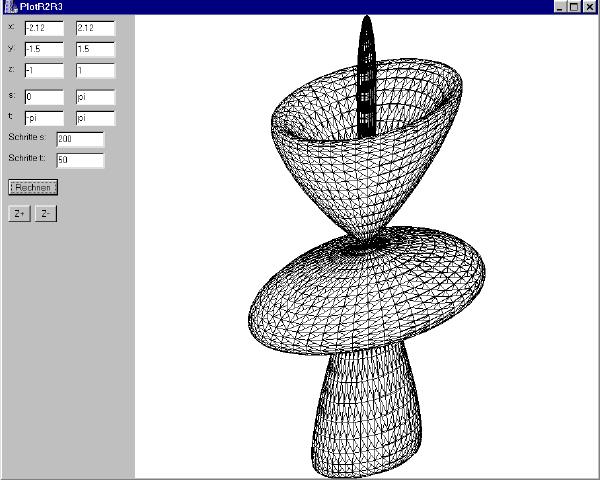
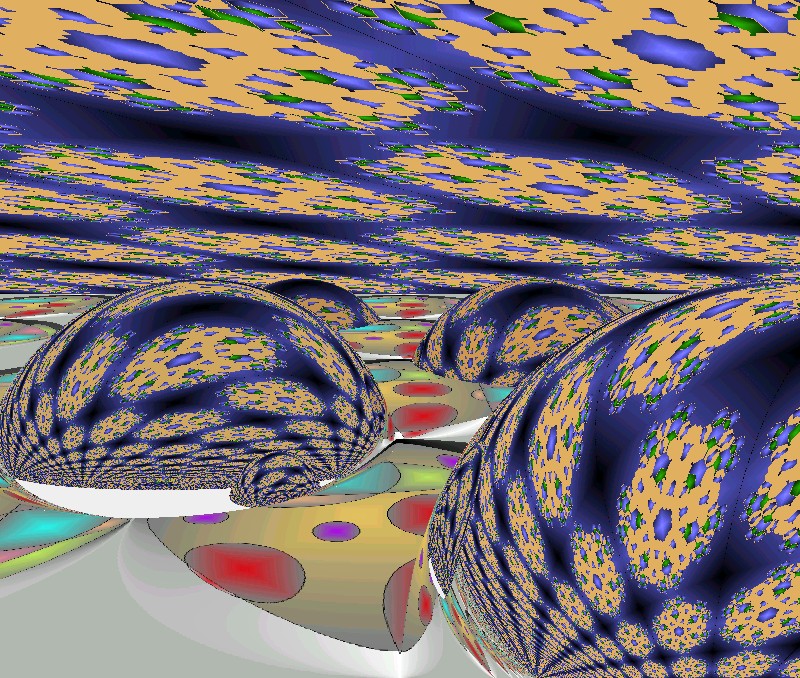
Die Koordinaten der Fläche werden durch drei Funktionen X(s,t), Y(s,t), Z(s,t) berechnet. Die Intervalle für s und t werden vom Benutzer gewählt, ebenso eine Anzahl Schritte, in die die Intervalle eingeteilt werden. Das Programm durchläuft das Intervall und ermittelt für je drei Punkte aus dem Intervall drei Punkte im Raum, die dann ein Dreieck ergeben. Diese Dreiecke werden in einer Liste abgelegt. Nach der Berechnung wird die Dreiecksliste so sortiert, dass die vom Betrachter am weitesten entfernten Flächen an den Anfang der Liste kommen. Dann wird die Liste gezeichnet, wobei jedes Dreieck mit der Hintergrundfarbe gefüllt wird. Dadurch verdecken die vorderen Flächen die hinteren.
Screenshot (20.000 Flächen):